Evolution of Enterprise Data Architectures: From BI to AI Data Lakehouses
Written by Raúl Galán. CTO MonoM, by Grupo Álava
January 9, 2024 | Business Inteligent and AI | Article






Evolution of Enterprise Data Architectures: From BI to AI Data Lakehouses
In today's business world, efficient data management is key to strategic decision making. Over the decades, we have witnessed an evolution in enterprise data architectures, from Business Intelligence (BI) through Data Lakes and their enhanced version, Data Lakehouses, and finally AI Data Lakehouses. Each paradigm has marked a milestone in data management, with its own strengths and challenges.
Business Intelligence (BI): Retrospective Perspective
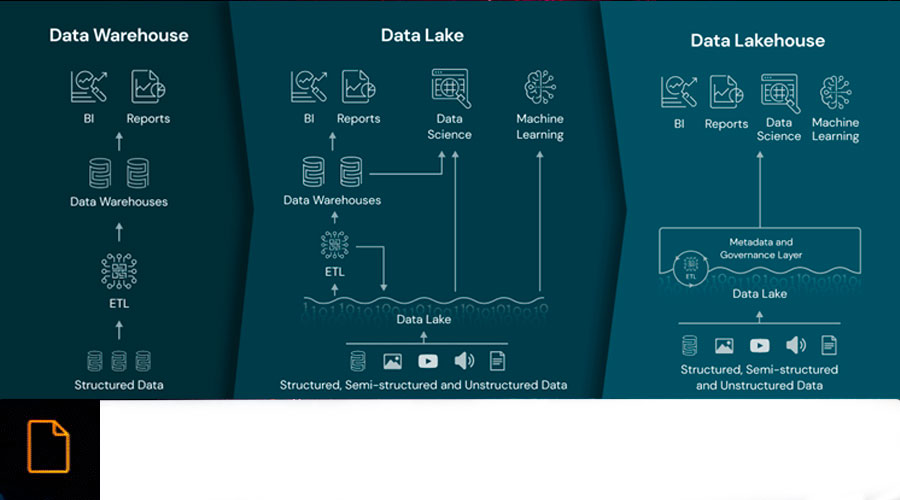
Business Intelligence (BI) was the starting point in data management. This approach focuses on analyzing historical data and generating static reports to provide a retrospective view of business performance. However, BI has limitations in managing large volumes of data or when data is unstructured, as well as in adaptability to changing analysis needs.
BI tools such as Tableau, Power BI and QlikView became the stars of this paradigm, enabling the creation of intuitive visualizations and executive summaries. These tools, along with others, made it easy for analysts and BI professionals to extract, transform and load (ETL) data from a variety of sources to generate reports that highlighted key trends, patterns and metrics.
In this technological context, BI engineers assumed a pivotal role. Their responsibility was to understand end-user reporting requirements and translate those requirements into database queries, data manipulation, and visual reporting. The implementation and maintenance of BI systems were closely tied to these professionals, who acted as key intermediaries between data and business needs.
The BI approach was initially designed to handle structured data sets for executive summaries. Organizations focused on capturing key data related to sales, finance and operations, with an emphasis on tabular and graphical reporting.
The systems were configured to provide users with immediate access to up-to-date reports, allowing for agile decision making based on recent data, although this information often had some lag.
Although BI provides valuable insight into the past, its limitation lies in its retrospective approach and its limited ability to handle large volumes of data, or when the nature of the data is unstructured or semi-structured. The demand for more agile and adaptive data management led to the next phase of evolution: the era of Data Lakes.
Data Lakes: Breaking Down Structural Barriers
As organizations sought to manage an increasing amount of unstructured and semi-structured data, Data Lakes emerged as an answer to the limitations of Business Intelligence. This paradigm marked a significant shift by allowing companies to store data in its rawest form, without imposing rigid structures beforehand.
The key to its operation lies in the use of distributed storage technologies, such as Apache Hadoop through its conceptualization as a service among which we can find Amazon S3 or GCS, which allow storing large volumes of data in its original form, whatever the nature of the data: structured, semi-structured or unstructured. In addition, distributed processing tools such as Apache Spark and Apache Flink are used to analyze and process this data in an efficient and scalable way.
Data engineers become central players in the implementation and maintenance of Data Lakes. Their role is to design scalable data architectures, configure ETL (Extract, Transform, Load) or even ELT workflows in order to move data to the Data Lake, and provide access to this data through query interfaces or analysis tools.
Data Lakes represented a significant change by enabling organizations to manage large volumes of unstructured and heterogeneous data. From plain text documents to multimedia files, Data Lakes were designed to accommodate a variety of data types without the need to define rigid structures in advance.
Data acquisition in a Data Lake often occurred without significant initial processing. The data was stored in raw form, preserving its integrity and allowing it to be explored and further processed according to analytical needs.
While Data Lakes provided the ability to store a wide range of data in a more flexible manner, significant challenges arose in terms of governance, data quality and efficient access. The massive accumulation of data without a robust structure led to the need for a further evolution in enterprise data management, giving way to the Data Lakehouse architecture.
Data Lakehouse: Joining Forces of Storage and Structure
In response to the governance and data quality challenges present in Data Lakes, the Data Lakehouse architecture emerged, marking an important milestone in the evolution of enterprise data architectures. This paradigm seeks a balance between the storage flexibility of Data Lakes and the structure of traditional Data Warehouses.
The key to the Data Lakehouse is the implementation of hybrid storage technologies that enable both the preservation of raw data and the application of structures. Platforms such as Delta Lake, which operates on top of storage systems such as Apache Hadoop or Amazon S3, offer the ability to store data in its raw form while applying schemes to improve quality and governance.
Data Lakehouse implementation is a collaborative effort between data engineers and BI engineers. Data engineers remain responsible for managing and maintaining the raw data storage, while BI engineers leverage the added structure to facilitate more efficient reporting and analysis.
Compared to traditional warehouses, data lakehouses have the capacity to handle data volumes ranging from gigabytes to petabytes. This makes it a scalable option for organizations with diverse data storage and analysis needs.
Unlike traditional Data Lakes, data acquisition in a Data Lakehouse involves initial processing to apply schemas and improve quality and governance. However, this offset is considerably smaller compared to the rigid structures of traditional Data Warehouses.
The combination of hybrid storage and structures in the Data Lakehouse seeks to overcome the limitations of its predecessors, offering flexibility to handle large volumes of data, while ensuring better control and governance over data quality. However, the evolution does not stop here, and the integration of artificial intelligence into the paradigm takes data management to an even more advanced level: the AI Data Lakehouse.
AI Data Lakehouse: Transformation with Artificial Intelligence
In the ongoing quest to optimize enterprise data management, the AI Data Lakehouse architecture represents a significant evolution by incorporating artificial intelligence (AI) into data governance and access. This paradigm not only maintains the fundamental features of the Data Lakehouse, but also leverages the predictive and adaptive capabilities of AI to improve decision making and operational efficiency.
AI Data Lakehouse integrates hybrid storage technologies, such as Delta Lake, with artificial intelligence and machine learning tools. AI libraries, such as TensorFlow or PyTorch, are combined with distributed processing systems to enable the application of Machine Learning models to stored data. Recently, a new player has come into play to close the circle: generative artificial intelligence. This technology allows access to information in a simple way for any type of user, as well as, through its generation capabilities, the creation of synthetic data to help fill gaps or perform simulations.
Implementing this paradigm involves collaboration between data engineers, BI engineers and data scientists. Data engineers remain essential for managing the storage and initial quality of data, while data scientists use AI to model patterns, predict behaviors and improve governance.
AI Data Lakehouse is capable of handling data volumes from gigabytes to petabytes, just like its predecessor. The ability to integrate AI into this environment offers greater flexibility to analyze large data sets and discover patterns that might go unnoticed using conventional methods.
Data acquisition in an AI Data Lakehouse involves initial processing, similar to the Data Lakehouse, but with an additional emphasis on AI-driven governance. Artificial intelligence is used to apply dynamic security policies, analyze access patterns and suggest data quality improvements, adding a predictive and adaptive component to the process.
Advantages of the AI Data Lakehouse
- Dynamic Governance: Artificial intelligence automates the application of governance policies, adapting to changes in real time and ensuring compliance.
- Personalized Access: AI analyzes access patterns to provide dynamic and personalized access to data, improving efficiency and security.
- Continuous Data Improvement: With automatic feedback from artificial intelligence, data quality can continuously evolve, eliminating duplication and improving consistency.
Challenges and Considerations
- Implementation Complexity: Artificial intelligence integration can be complex, requiring significant investments in infrastructure and training.
- Ethics and Privacy: Data management with artificial intelligence poses ethical and privacy challenges, which must be addressed with transparency and accountability.
- Specialized Skills: Successful implementation of AI Data Lakehouse requires specialized skills and knowledge, which can be challenging for some organizations.
The evolution of enterprise data architectures reflects the constant search for more efficient and versatile solutions. From Business Intelligence to AI Data Lakehouses, each phase has contributed to the improvement of data management, paving the way for more informed and agile decision making in the competitive business landscape.
Share this article!

Industry 4.0: basic concepts and background
Industry 4.0: [...]

Challenges and opportunities for AI and robotics in the offshore wind energy sector.
Challenges and [...]

Strategies for effective data collection and management in predictive maintenance.
Strategies for [...]

The Remote Monitoring Revolution in Wind Farms
The Revolution [...]

Infrastructure digitization: how the cloud and Big Data are transforming civil engineering.
Digitization of [...]