

Evolução das arquitecturas de dados empresariais: do BI aos Data Lakehouses com IA
Escrito por Raúl Galán. CTO MonoM, do Grupo Álava
9 de janeiro de 2024 | Business Inteligent e IA | Artigo






Evolução das arquitecturas de dados empresariais: do BI aos Data Lakehouses com IA
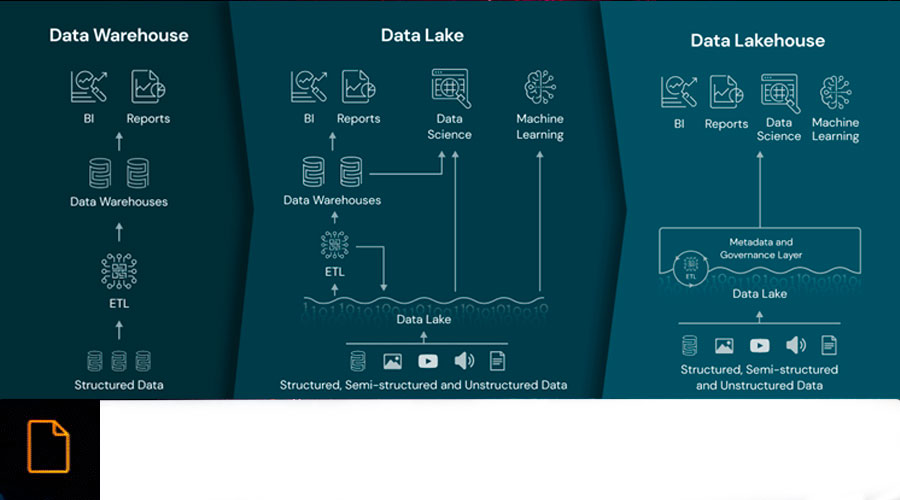
No mundo empresarial atual, a gestão eficiente dos dados é fundamental para a tomada de decisões estratégicas. Ao longo das décadas, assistimos a uma evolução nas arquitecturas de dados empresariais, desde o Business Intelligence (BI) até aos Data Lakes e à sua versão melhorada, os Data Lakehouses e, finalmente, os AI Data Lakehouses. Cada paradigma constituiu um marco na gestão de dados, com os seus próprios pontos fortes e desafios.
Business Intelligence (BI): Perspetiva Retrospetiva
O Business Intelligence (BI) foi o ponto de partida da gestão de dados. Esta abordagem centra-se na análise de dados históricos e na geração de relatórios estáticos para fornecer uma visão retrospetiva do desempenho da empresa. No entanto, a BI tem limitações na gestão de grandes volumes de dados ou quando os dados não estão estruturados, bem como na adaptabilidade à evolução das necessidades analíticas.
As ferramentas de BI como o Tableau, Power BI e QlikView tornaram-se as estrelas deste paradigma, permitindo a criação de visualizações intuitivas e resumos executivos. Estas ferramentas, juntamente com outras, tornaram mais fácil para os analistas e profissionais de BI extrair, transformar e carregar (ETL) dados de uma variedade de fontes para gerar relatórios que destacavam as principais tendências, padrões e métricas.
Neste contexto tecnológico, os engenheiros de BI assumiram um papel fundamental. A sua responsabilidade consistia em compreender as necessidades de informação dos utilizadores finais e traduzi-las em consultas de bases de dados, manipulação de dados e relatórios visuais. A implementação e a manutenção dos sistemas de BI estavam estreitamente ligadas a estes profissionais, que actuavam como intermediários fundamentais entre os dados e as necessidades da empresa.
A abordagem de BI foi inicialmente concebida para tratar conjuntos de dados estruturados para resumos executivos. As organizações concentraram-se na recolha de dados-chave relacionados com vendas, finanças e operações, com ênfase em relatórios tabulares e gráficos.
Os sistemas foram configurados para fornecer aos utilizadores acesso imediato a relatórios actualizados, permitindo uma tomada de decisão ágil com base em dados recentes, embora esta informação tenha frequentemente algum desfasamento.
Embora o BI forneça informações valiosas sobre o passado, a sua limitação reside na sua abordagem retrospetiva e na sua capacidade limitada de lidar com grandes volumes de dados, ou quando a natureza dos dados é não estruturada ou semi-estruturada. A procura de uma gestão de dados mais ágil e adaptável conduziu à fase seguinte da evolução: a era dos Data Lakes.
Lagos de dados: quebrar barreiras estruturais
À medida que as organizações procuravam gerir uma quantidade crescente de dados não estruturados e semi-estruturados, os Data Lakes surgiram como uma resposta às limitações do Business Intelligence. Este paradigma marcou uma mudança significativa ao permitir que as empresas armazenassem dados na sua forma mais crua, sem impor estruturas rígidas de antemão.
A chave do seu funcionamento reside na utilização de tecnologias de armazenamento distribuído, como o Apache Hadoop e a sua concetualização como um serviço, incluindo o Amazon S3 ou o GCS, que permitem armazenar grandes volumes de dados na sua forma original, independentemente da natureza dos dados: estruturados, semi-estruturados ou não estruturados. Além disso, são utilizadas ferramentas de processamento distribuído, como o Apache Spark e o Apache Flink, para analisar e processar estes dados de forma eficiente e escalável.
Os engenheiros de dados tornam-se actores centrais na implementação e manutenção dos Data Lakes. O seu papel consiste em conceber arquitecturas de dados escaláveis, configurar fluxos de trabalho ETL (Extract, Transform, Load) ou mesmo ELT para transferir dados para o Data Lake e fornecer acesso a estes dados através de interfaces de consulta ou ferramentas de análise.
Os Data Lakes representaram uma mudança significativa ao permitirem às organizações gerir grandes volumes de dados não estruturados e heterogéneos. Desde documentos de texto simples a ficheiros multimédia, os Data Lakes foram concebidos para acomodar uma variedade de tipos de dados sem a necessidade de definir previamente estruturas rígidas.
A aquisição de dados num Data Lake ocorreu frequentemente sem um processamento inicial significativo. Os dados eram armazenados em bruto, preservando a sua integridade e permitindo a exploração e o processamento posterior de acordo com as necessidades analíticas.
Embora os Data Lakes tenham proporcionado a capacidade de armazenar uma vasta gama de dados de uma forma mais flexível, surgiram desafios significativos em termos de governação, qualidade dos dados e acesso eficiente. A acumulação maciça de dados sem uma estrutura sólida levou à necessidade de uma nova evolução na gestão de dados empresariais, dando lugar à arquitetura Data Lakehouse.
Data Lakehouse: Unir as forças do armazenamento e da estrutura
Em resposta aos desafios de governação e de qualidade dos dados presentes nos Data Lakes, surgiu a arquitetura Data Lakehouse, que constitui um marco importante na evolução das arquitecturas de dados empresariais. Este paradigma procura um equilíbrio entre a flexibilidade de armazenamento dos Data Lakes e a estrutura dos Data Warehouses tradicionais.
A chave para o Data Lakehouse é a implementação de tecnologias de armazenamento híbrido que permitem tanto a preservação de dados em bruto como a aplicação de estruturas. Plataformas como o Delta Lake, que funciona com base em sistemas de armazenamento como o Apache Hadoop ou o Amazon S3, oferecem a capacidade de armazenar dados na sua forma bruta, aplicando simultaneamente esquemas para melhorar a qualidade e a governação.
A implementação do Data Lakehouse é um esforço de colaboração entre os engenheiros de dados e os engenheiros de BI. Os engenheiros de dados continuam a ser responsáveis pela gestão e manutenção do armazém de dados brutos, enquanto os engenheiros de BI tiram partido da estrutura adicionada para facilitar a elaboração de relatórios e análises mais eficientes.
Em comparação com os armazéns tradicionais, os data lakehouses têm a capacidade de lidar com volumes de dados que vão desde gigabytes a petabytes. Isto torna-o uma opção escalável para organizações com diversas necessidades de armazenamento e análise de dados.
Ao contrário dos Data Lakes tradicionais, a aquisição de dados num Data Lakehouse envolve um processamento inicial para aplicar esquemas e melhorar a qualidade e a governação. No entanto, este desfasamento é consideravelmente menor em comparação com as estruturas rígidas dos Data Warehouses tradicionais.
A combinação de armazenamento híbrido e estruturas no Data Lakehouse procura ultrapassar as limitações dos seus antecessores, oferecendo flexibilidade para lidar com grandes volumes de dados, ao mesmo tempo que garante um melhor controlo e governação da qualidade dos dados. No entanto, a evolução não pára por aqui e a integração da inteligência artificial no paradigma leva a gestão de dados a um nível ainda mais avançado: o AI Data Lakehouse.
AI Data Lakehouse: Transformar com Inteligência Artificial
Na procura contínua de otimizar a gestão de dados empresariais, a arquitetura AI Data Lakehouse representa uma evolução significativa ao incorporar a inteligência artificial (IA) na governação e no acesso aos dados. Este paradigma não só mantém as características principais do Data Lakehouse, como também tira partido das capacidades preditivas e adaptativas da IA para melhorar a tomada de decisões e a eficiência operacional.
O AI Data Lakehouse integra tecnologias de armazenamento híbrido, como o Delta Lake, com inteligência artificial e ferramentas de aprendizagem automática. As bibliotecas de IA, como o TensorFlow ou o PyTorch, são combinadas com sistemas de processamento distribuídos para permitir a aplicação de modelos de aprendizagem automática aos dados armazenados. Recentemente, um novo ator entrou em cena para fechar o círculo: a inteligência artificial generativa. Esta tecnologia permite o acesso à informação de uma forma simples para qualquer tipo de utilizador, bem como, através das suas capacidades de geração, a criação de dados sintéticos para ajudar a preencher lacunas ou realizar simulações.
A implementação deste paradigma implica a colaboração entre engenheiros de dados, engenheiros de BI e cientistas de dados. Os engenheiros de dados continuam a ser essenciais para gerir o armazenamento e a qualidade inicial dos dados, enquanto os cientistas de dados utilizam a IA para modelar padrões, prever comportamentos e melhorar a governação.
O AI Data Lakehouse é capaz de lidar com volumes de dados de gigabytes a petabytes, tal como o seu antecessor. A capacidade de integrar a IA neste ambiente oferece uma maior flexibilidade para analisar grandes conjuntos de dados e descobrir padrões que poderiam passar despercebidos utilizando métodos convencionais.
A aquisição de dados numa AI Data Lakehouse envolve o processamento inicial, semelhante ao da Data Lakehouse, mas com uma ênfase adicional na governação orientada para a IA. A inteligência artificial é utilizada para aplicar políticas de segurança dinâmicas, analisar padrões de acesso e sugerir melhorias na qualidade dos dados, acrescentando uma componente preditiva e adaptativa ao processo.
Vantagens do lago de dados de IA
- Governação dinâmica: A inteligência artificial automatiza a aplicação de políticas de governação, adaptando-se às mudanças em tempo real e garantindo a conformidade.
- Acesso personalizado: a IA analisa os padrões de acesso para proporcionar um acesso dinâmico e personalizado aos dados, melhorando a eficiência e a segurança.
- Melhoria contínua dos dados: Com o feedback automático da inteligência artificial, a qualidade dos dados pode evoluir continuamente, eliminando a duplicação e melhorando a consistência.
Desafios e considerações
- Complexidade de implementação: A integração da inteligência artificial pode ser complexa, exigindo investimentos significativos em infra-estruturas e formação.
- Ética e privacidade: A gestão de dados com inteligência artificial levanta desafios éticos e de privacidade, que devem ser abordados com transparência e responsabilidade.
- Competências especializadas: A implementação bem sucedida do AI Data Lakehouse requer competências e conhecimentos especializados, o que pode ser um desafio para algumas organizações.
A evolução das arquitecturas de dados empresariais reflecte a procura constante de soluções mais eficientes e versáteis. Desde o Business Intelligence até aos Data Lakehouses com IA, cada fase contribuiu para a melhoria da gestão de dados, abrindo caminho para uma tomada de decisões mais informada e ágil no panorama empresarial competitivo.
Partilhar este artigo!

Indústria 4.0: conceitos básicos e antecedentes
Indústria 4.0: [...]

Desafios e oportunidades para a IA e a robótica no sector eólico offshore
Desafios e [...]

Estratégias para a recolha e gestão eficazes de dados na manutenção preditiva
Estratégias para [...]

A revolução da monitorização remota em parques eólicos
A Revolução [...]

Digitalização das infra-estruturas: como a nuvem e os grandes dados estão a transformar a engenharia civil
Digitalização de [...]
Evolução das arquitecturas de dados empresariais: do BI aos Data Lakehouses com IA
A evolução das arquitecturas de dados empresariais: do BI [...]
Contacto
Fale com os nossos
especialistas
Encontrará na nossa equipa um grande apoio para abordar com êxito o seu projeto de digitalização industrial.
o seu projeto de digitalização industrial com sucesso. Após horas de trabalho intensivo
de trabalho intensivo e um ou dois cafés pelo caminho, garantiremos que obtém a
a solução que melhor se adapta às suas necessidades.