

Evolución de las Arquitecturas de Datos Empresariales: Del BI a los AI Data Lakehouses
Escrito por Raúl Galán. CTO MonoM, by Grupo Álava
9 de enero de 2024 | Business Inteligent y AI | Artículo




Evolución de las Arquitecturas de Datos Empresariales: Del BI a los AI Data Lakehouses
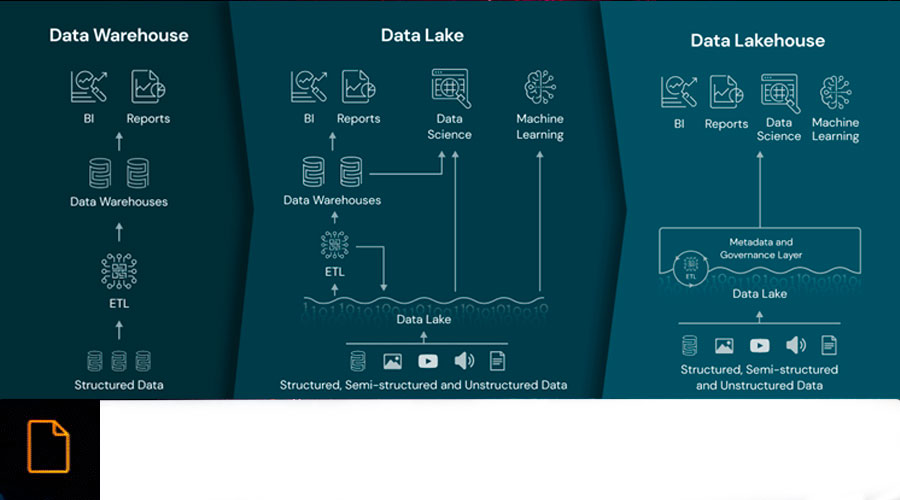
En el mundo empresarial actual, la gestión eficiente de los datos es clave para la toma de decisiones estratégicas. A lo largo de las décadas, hemos sido testigos de una evolución en las arquitecturas de datos empresariales, desde el Business Intelligence (BI) pasando por los Data Lakes y su versión mejorada, los Data Lakehouses, y, finalmente, los AI Data Lakehouses. Cada paradigma ha marcado un hito en la gestión de datos, con sus propias fortalezas y desafíos.
Business Intelligence (BI): Perspectiva Retrospectiva
El Business Intelligence (BI) fue el punto de partida en la gestión de datos. Este enfoque se centra en analizar datos históricos y generar informes estáticos para proporcionar una visión retrospectiva del rendimiento empresarial. Sin embargo, BI presenta limitaciones en la gestión de grandes volúmenes de datos o cuando éstos no son estructurados, así como en la adaptabilidad a cambios en las necesidades de análisis.
Las herramientas de BI, como Tableau, Power BI y QlikView, se convirtieron en las estrellas de este paradigma, permitiendo la creación de visualizaciones intuitivas y resúmenes ejecutivos. Estas herramientas, junto a otras, facilitaron a los analistas y profesionales de BI la tarea de extraer, transformar y cargar (ETL) datos desde diversas fuentes para generar informes que destacaran tendencias, patrones y métricas clave.
En este contexto tecnológico, los ingenieros de BI asumieron un papel capital. Su responsabilidad era comprender los requisitos de informes de los usuarios finales y traducir esos requisitos en consultas a las bases de datos, manipulación de datos y creación de informes visuales. La implementación y mantenimiento de sistemas BI estaban estrechamente vinculados a estos profesionales, quienes actuaban como intermediarios clave entre los datos y las necesidades comerciales.
El enfoque de BI estaba inicialmente diseñado para manejar conjuntos de datos estructurados para la confección de resúmenes ejecutivos. Las organizaciones se centraban en la captura de datos clave relacionados con ventas, finanzas y operaciones, con un énfasis en la presentación de informes tabulares y gráficos.
Los sistemas estaban configurados para proporcionar a los usuarios acceso inmediato a los informes actualizados, lo que permitía una toma de decisiones ágil basada en datos recientes, aunque a menudo esta información tenía cierto decalaje.
Aunque el BI proporciona una visión valiosa del pasado, su limitación radica en su enfoque retrospectivo y su capacidad limitada para manejar grandes volúmenes de datos, o bien cuando la naturaleza de los mismos es de tipo no estructurado o semiestructurados. La demanda de una gestión de datos más ágil y adaptativa llevó a la siguiente fase de evolución: la era de los Data Lakes.
Data Lakes: Rompiendo Barreras de Estructura
A medida que las organizaciones buscaban gestionar una creciente cantidad de datos no estructurados y semiestructurados, surgieron los Data Lakes como una respuesta a las limitaciones del Business Intelligence. Este paradigma marcó un cambio significativo al permitir a las empresas almacenar datos en su forma más cruda, sin imponer estructuras rígidas de antemano.
La clave de su funcionamiento radica en el uso de tecnologías de almacenamiento distribuido, como Apache Hadoop pasando por su conceptualización como servicio entre los que podemos encontrar Amazon S3 o GCS, que permiten almacenar grandes volúmenes de datos en su forma original, sea cual sea la naturaleza del dato: estructurada, semiestructurada o no estructurada. Además, herramientas de procesamiento distribuido como Apache Spark y Apache Flink se utilizan para analizar y procesar estos datos de manera eficiente y escalable.
Los ingenieros de datos se convirtien en actores centrales en la implementación y mantenimiento de Data Lakes. Su función consiste en diseñar arquitecturas de datos escalables, configurar flujos de trabajo ETL (Extract, Transform, Load) o incluso ELT con el fin de mover datos al Data Lake, y proporcionar acceso a estos datos a través de interfaces de consulta o herramientas de análisis.
Data Lakes representó un cambio significativo al permitir a las organizaciones gestionar grandes volúmenes de datos no estructurados y heterogéneos. Desde documentos de texto sin formato hasta archivos multimedia, los Data Lakes fueron diseñados para albergar una variedad de tipos de datos sin la necesidad de definir estructuras rígidas de antemano.
La adquisición de datos en un Data Lake a menudo ocurría sin un procesamiento inicial significativo. Los datos se almacenaban en bruto, preservando su integridad y permitiendo su exploración y procesamiento posterior según las necesidades analíticas.
Aunque los Data Lakes proporcionaron la capacidad de almacenar una amplia gama de datos de manera más flexible, surgieron desafíos significativos en términos de gobernanza, calidad de datos y acceso eficiente. La acumulación masiva de datos sin una estructura sólida llevó a la necesidad de una evolución adicional en la gestión de datos empresariales, dando paso a la arquitectura de Data Lakehouse.
Data Lakehouse: Uniendo Fuerzas de Almacenamiento y Estructura
En respuesta a los desafíos de gobernanza y calidad de datos presentes en los Data Lakes, surge la arquitectura de Data Lakehouse, marcando un hito importante en la evolución de las arquitecturas de datos empresariales. Este paradigma busca un equilibrio entre la flexibilidad de almacenamiento de los Data Lakes y la estructura de los Data Warehouses tradicionales.
La clave del Data Lakehouse es la implementación de tecnologías de almacenamiento híbridas que permiten tanto la preservación de datos en bruto como la aplicación de estructuras. Plataformas como Delta Lake, que opera sobre sistemas de almacenamiento como Apache Hadoop o Amazon S3, ofrecen la capacidad de almacenar datos en su forma cruda mientras aplican esquemas para mejorar la calidad y la gobernanza.
La implementación de Data Lakehouse es un esfuerzo colaborativo entre ingenieros de datos e ingenieros de BI. Los ingenieros de datos siguen siendo responsables de la gestión y mantenimiento del almacenamiento de datos en bruto, mientras que los ingenieros de BI aprovechan la estructura añadida para facilitar la creación de informes y análisis más eficientes.
Frente a los Warehouses tradicionales, los Data Lakehouses tienen la capacidad de manejar volúmenes de datos que varían desde gigabytes hasta petabytes. Esto lo convierte en una opción escalable para organizaciones con diversas necesidades de almacenamiento y análisis de datos.
A diferencia de los Data Lakes tradicionales, la adquisición de datos en un Data Lakehouse involucra un procesamiento inicial para aplicar esquemas y mejorar la calidad y la gobernanza. Sin embargo, este decalaje es considerablemente menor en comparación con las estructuras rígidas de los Data Warehouses tradicionales.
La combinación de almacenamiento híbrido y estructuras en el Data Lakehouse busca superar las limitaciones de sus predecesores, ofreciendo flexibilidad para manejar grandes volúmenes de datos, al tiempo que garantiza un mejor control y gobierno sobre la calidad de los datos. No obstante, la evolución no se detiene aquí, y la integración de inteligencia artificial en el paradigma lleva la gestión de datos a un nivel aún más avanzado: el AI Data Lakehouse.
AI Data Lakehouse: Transformación con Inteligencia Artificial
En la búsqueda continua de optimizar la gestión de datos empresariales, la arquitectura de AI Data Lakehouse representa una evolución significativa al incorporar inteligencia artificial (IA) en la gobernanza y el acceso a los datos. Este paradigma no solo mantiene las características fundamentales del Data Lakehouse, sino que también aprovecha la capacidad predictiva y adaptativa de la IA para mejorar la toma de decisiones y la eficiencia operativa.
AI Data Lakehouse integra tecnologías de almacenamiento híbridas, como Delta Lake, con herramientas de inteligencia artificial y aprendizaje automático. Librerías de IA como TensorFlow o PyTorch, se combinan con sistemas de procesamiento distribuido para permitir la aplicación de modelos de Machine Learning a los datos almacenados. Desde hace poco un nuevo actor ha entrado en juego cerrando el círculo: la inteligencia artificial generativa. Esta tecnología permite el acceso a la información de una manera simple para cualquier tipo de usuario, así como, mediante sus capacidades de generación, creación de datos sintéticos que ayuden a cubrir huecos o realizar simulaciones.
La implementación de este paradigma implica la colaboración entre ingenieros de datos, ingenieros de BI y científicos de datos. Los ingenieros de datos siguen siendo esenciales para gestionar el almacenamiento y la calidad inicial de los datos, mientras que los científicos de datos utilizan la IA para modelar patrones, predecir comportamientos y mejorar la gobernanza.
AI Data Lakehouse es capaz de manejar volúmenes de datos desde gigabytes hasta petabytes, al igual que su predecesor. La capacidad de integrar IA en este entorno ofrece una mayor flexibilidad para analizar grandes conjuntos de datos y descubrir patrones que podrían pasar desapercibidos mediante métodos convencionales.
La adquisición de datos en un AI Data Lakehouse involucra un procesamiento inicial, similar al Data Lakehouse, pero con un énfasis adicional en la gobernanza impulsada por IA. La inteligencia artificial se utiliza para aplicar políticas de seguridad dinámicas, analizar patrones de acceso y sugerir mejoras en la calidad de los datos, lo que agrega un componente predictivo y adaptativo al proceso.
Ventajas del AI Data Lakehouse
- Gobernanza Dinámica: La inteligencia artificial automatiza la aplicación de políticas de gobernanza, adaptándose a cambios en tiempo real y garantizando la conformidad.
- Acceso Personalizado: La IA analiza patrones de acceso para proporcionar acceso dinámico y personalizado a los datos, mejorando la eficiencia y la seguridad.
- Mejora Continua de Datos: Con la retroalimentación automática de la inteligencia artificial, la calidad de los datos puede evolucionar de manera continua, eliminando duplicaciones y mejorando la consistencia.
Desafíos y Consideraciones
- Complejidad de Implementación: La integración de inteligencia artificial puede ser compleja, requiriendo inversiones significativas en infraestructura y capacitación.
- Ética y Privacidad: La gestión de datos con inteligencia artificial plantea desafíos éticos y de privacidad, que deben abordarse con transparencia y responsabilidad.
- Habilidades Especializadas: La implementación exitosa de AI Data Lakehouse requiere habilidades y conocimientos especializados, lo que puede representar un desafío para algunas organizaciones.
La evolución de las arquitecturas de datos empresariales refleja la búsqueda constante de soluciones más eficientes y versátiles. Desde el Business Intelligence hasta los AI Data Lakehouses, cada fase ha contribuido a la mejora de la gestión de datos, allanando el camino hacia una toma de decisiones más informada y ágil en el competitivo panorama empresarial.
¡Comparte este artículo!

Estrategias para la recopilación y gestión eficaz de datos en el mantenimiento predictivo
Estrategias para […]

La Revolución de la Monitorización en Remoto en los Parques Eólicos
La Revolución […]

Digitalización de infraestructuras: cómo la nube y el Big Data están transformando la ingeniería civil
Digitalización de […]
Evolución de las Arquitecturas de Datos Empresariales: Del BI a los AI Data Lakehouses
Evolución de las Arquitecturas de Datos Empresariales: Del BI […]

La Convergencia de la Tecnología y la Fabricación: Hacia la Revolución Industrial 4.0
La Convergencia […]

Diseño de prompts para su utilización en IA generativa
Diseño de prompts para su utilización en IA generativa […]